调用链路追踪
调用链路追踪
介绍
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个 trace。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个 span。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有 span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
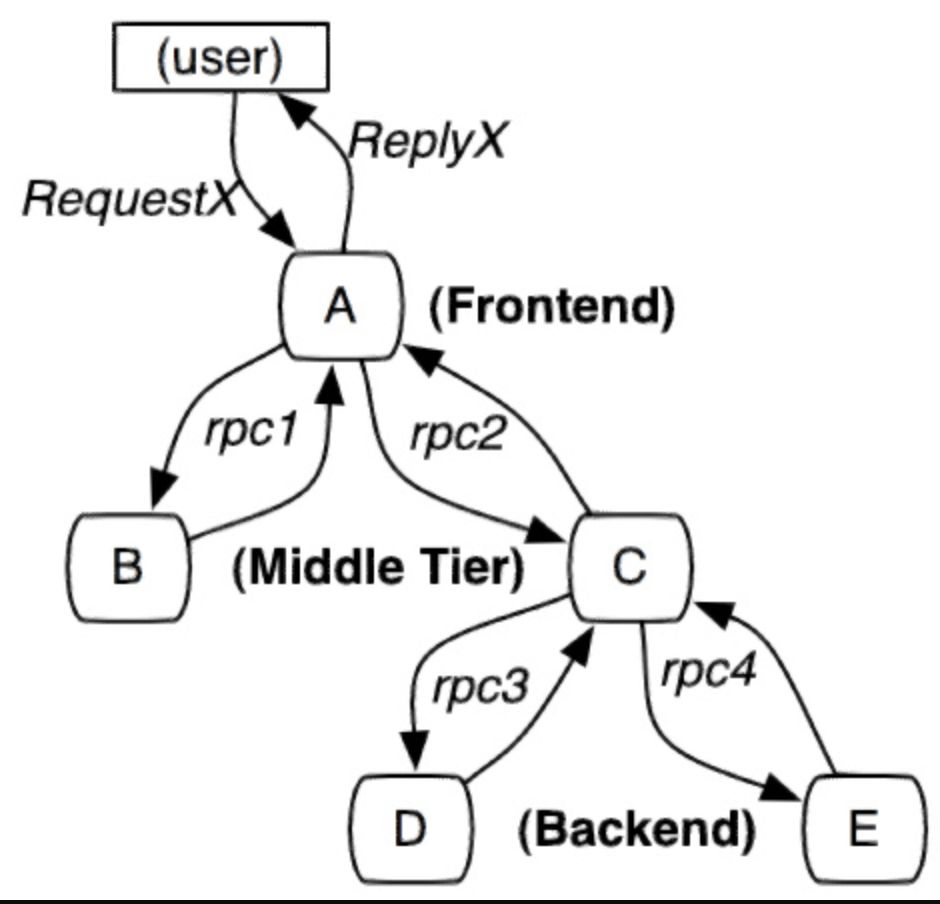
Spring Cloud Sleuth 为服务之间调用提供链路追踪。通过 Sleuth 可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外 Sleuth 可以帮助我们:
-
耗时分析: 通过 Sleuth 可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
-
链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
-
可视化错误: 对于程序未捕捉的异常,可以通过集成 Zipkin 服务界面上看到; Spring Cloud Sleuth 可以结合 Zipkin,将信息发送到 Zipkin,利用 Zipkin 的存储来存储信息,利用 Zipkin UI 来展示数据。
https://zipkin.io/pages/quickstart
启动zipkin
apiVersion: apps/v1
kind: Deployment
metadata:
name: zipkin
namespace: luffy
spec:
replicas: 1
selector:
matchLabels:
app: zipkin
template:
metadata:
labels:
app: zipkin
spec:
containers:
- name: zipkin
image: openzipkin/zipkin:2.22
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9411
resources:
requests:
memory: 400Mi
cpu: 50m
limits:
memory: 2Gi
cpu: 2000m
---
apiVersion: v1
kind: Service
metadata:
name: zipkin
namespace: luffy
spec:
ports:
- port: 9411
protocol: TCP
targetPort: 9411
selector:
app: zipkin
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: zipkin
namespace: luffy
spec:
ingressClassName: nginx
rules:
- host: zipkin.luffy.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: zipkin
port:
number: 9411
实践
分别对bill-service和user-service进行改造:
pom.xml中添加:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
application.yml
spring:
zipkin:
base-url: http://zipkin.luffy.com # zipkin服务器的地址
sender:
type: web # 设置使用http的方式传输数据
sleuth:
sampler:
probability: 1 # 设置抽样采集为100%,默认为0.1,即10%
logging:
level:
org.springframework.cloud: debug
访问zuul网关的接口http://localhost:10000/apis/bill-service/bill/user/2