基于Label的动态告警处理
基于Label的动态告警处理
真实的场景中,我们往往期望可以给告警设置级别,而且可以实现不同的报警级别可以由不同的receiver接收告警消息。
Alertmanager中路由负责对告警信息进行分组匹配,并向告警接收器发送通知。告警接收器可以通过以下形式进行配置:
routes:
- receiver: ops
group_wait: 10s
match:
severity: critical
- receiver: dev
group_wait: 10s
match_re:
severity: normal|middle
receivers:
- ops
...
- dev
...
- \<receiver\> ...
因此可以为了更全面的感受报警的逻辑,我们再添加两个报警规则:
alert_rules.yml: |
groups:
- name: node_metrics
rules:
- alert: NodeLoad
expr: node_load15 \< 1
for: 2m
labels:
severity: normal
annotations:
summary: "{{$labels.instance}}: Low node load detected"
description: "{{$labels.instance}}: node load is below 1 (current value is: {{ $value }}"
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 \> 30
for: 2m
labels:
severity: critical
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 40% (current value is: {{ $value }}"
- name: targets_status
rules:
- alert: TargetStatus
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "{{$labels.instance}}: prometheus target down"
description: "{{$labels.instance}}: prometheus target down,job is {{$labels.job}}"
我们为不同的报警规则设置了不同的标签,如severity: critical,针对规则中的label,来配置alertmanager路由规则,实现转发给不同的接收者。
$ cat alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor
data:
config.yml: |-
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'earlene163@163.com'
smtp_auth_username: 'earlene163@163.com'
# 注意这里不是邮箱密码,是邮箱开启第三方客户端登录后的授权码
smtp_auth_password: 'RMAOPQVHKLPYFVHZ'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 按照告警名称分组
group_by: ['alertname']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 相同的group之间发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间��来重新发送他们,不同类型告警发送频率需要具体配置
repeat_interval: 1m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 路由树,默认继承global中的配置,并且可以在每个子路由上进行覆盖。
routes:
- receiver: critical_alerts
group_wait: 10s
match:
severity: critical
- receiver: normal_alerts
group_wait: 10s
match_re:
severity: normal|middle
receivers:
- name: 'default'
email_configs:
- to: '654147123@qq.com'
send_resolved: true # 接受告警恢复的通知
- name: 'critical_alerts'
webhook_configs:
- send_resolved: true
url: http://webhook-dingtalk:8060/dingtalk/webhook_ops/send
- name: 'normal_alerts'
webhook_configs:
- send_resolved: true
url: http://webhook-dingtalk:8060/dingtalk/webhook_dev/send
再配置一个钉钉机器人,修改webhook-dingtalk的配置,添加webhook_ops的配置:
$ cat webhook-dingtalk-configmap.yaml
apiVersion: v1
data:
config.yml: |
targets:
webhook_dev:
url: https://oapi.dingtalk.com/robot/send?access_token=f628f749a7ad70e86ca7bcb68658d0ce5af7c201ce8ce32acaece4c592364ca9
webhook_ops:
url: https://oapi.dingtalk.com/robot/send?access_token=5a68888fbecde75b1832ff024d7374e51f2babd33f1078e5311cdbb8e2c00c3a
kind: ConfigMap
metadata:
name: webhook-dingtalk-config
namespace: monitor
分别更新Prometheus和Alertmanager配置,查看报警的发送。
抑制和静默
前面我们知道,告警的group(分�组)功能通过把多条告警数据聚合,有效的减少告警的频繁发送。除此之外,Alertmanager还支持Inhibition(抑制) 和 Silences(静默),帮助我们抑制或者屏蔽报警。
-
Inhibition 抑制
抑制是当出现其它告警的时候压制当前告警的通知,可以有效的防止告警风暴。
比如当机房出现网络故障时,所有服务都将不可用而产生大量服务不可用告警,但这些警告并不能反映真实问题在哪,真正需要发出的应该是网络故障告警。当出现网络故障告警的时候,应当抑制服务不可用告警的通知。
在Alertmanager配置文件中,使用inhibit_rules定义一组告警的抑制规则:
inhibit_rules:
[ - <inhibit_rule> ... ]每一条抑制规则的具体配置如下:
target_match:
[ <labelname>: <labelvalue>, ... ]
target_match_re:
[ <labelname>: <regex>, ... ]
source_match:
[ <labelname>: <labelvalue>, ... ]
source_match_re:
[ <labelname>: <regex>, ... ]
[ equal: '[' <labelname>, ... ']' ]当已经发送的告警通知匹配到target_match或者target_match_re规则,当有新的告警规则如果满足source_match或者定义的匹配规则,并且已发送的告警与新产生的告警中equal定义的标签完全相同,则启动抑制机制,新的告警不会发送。
例如,定义如下抑制规则:
- source_match:
alertname: NodeDown
severity: critical
target_match:
severity: critical
equal:
- node如当集群中的某一个主机节点异常宕机导致告警NodeDown被触发,同时在告警规则中定义了告警级别severity=critical。由于主机异常宕机,该主机上部署的所有服务,中间件会不可用并触发报警。根据抑制规则的定义,如果有新的告警级别为severity=critical,并且告警中标签node的值与NodeDown告警的相同,则说明新的告警是由NodeDown导致的,则启动抑制机制停止向接收器发送通知。
演示:当告警名为NodeMemorUsage发生时,抑制告警告级为normal,以及labels标签中instance与NodeMemorUsage相同的项目告警
inhibit_rules:
- source_match:
alertname: NodeMemoryUsage
severity: critical
target_match:
severity: normal;
equal:
- instance -
Silences: 静默
简单直接的在指定时段关闭告警。静默通过匹配器(Matcher)来配置,类似于路由树。警告进入系统的时候会检查它是否匹配某条静默规则,如果是则该警告的通知将忽略。 静默规则在Alertmanager的 Web 界面里配置。
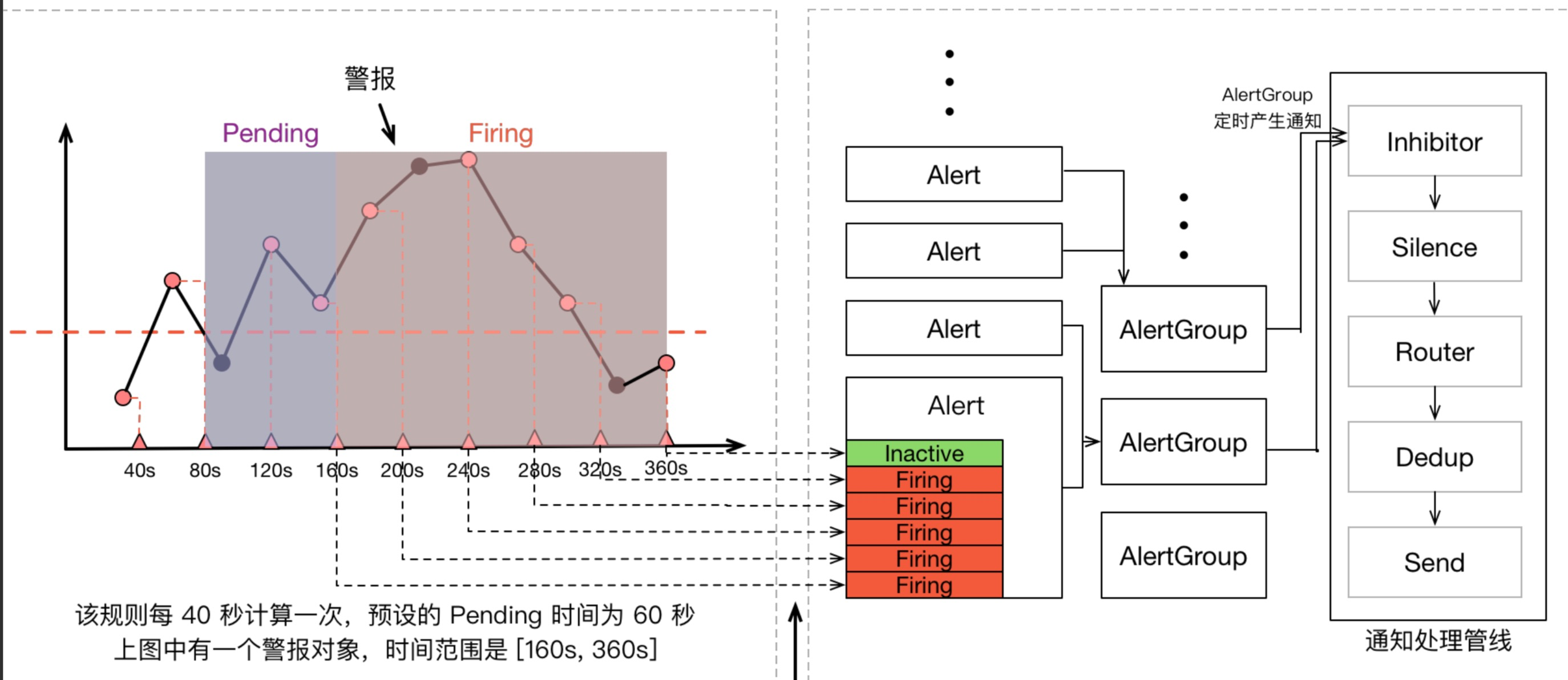
一条告警产生后,还要经过 Alertmanager 的分组、抑制处理、静默处理、去重处理和降噪处理最后再发送给接收者。这个过程中可能会因为各种原因会导致告警产生了却最终没有进行通知,可以通过下图了解整个告警的生命周期: