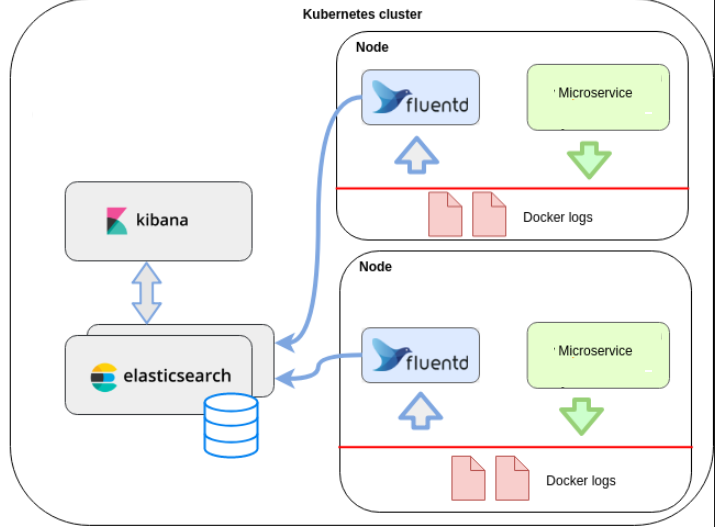
EFK架构工作流程
EFK架构工作流程
-
Elasticsearch
一个开源的分布式、Restful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。它可以被下面这样准确地形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索;
- 一个分布式实时分析搜索引擎;
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
-
Kibana
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。可以通过Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。也可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可�视化数据。
-
一个针对日志的收集、处理、转发系统。通过丰富的插件系统,可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
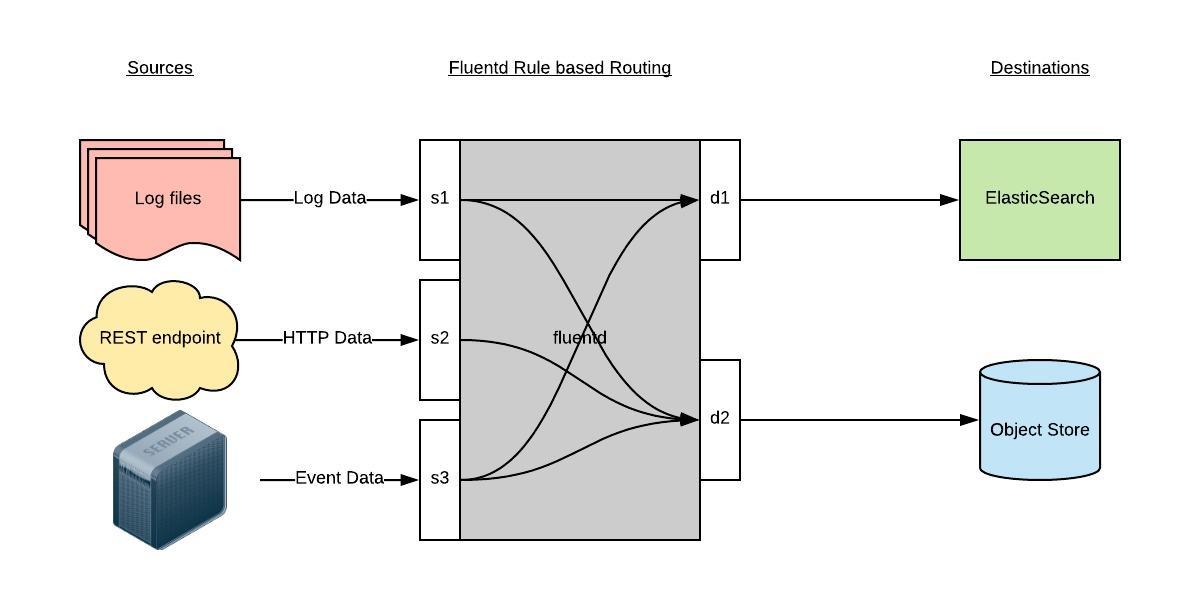
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储、kafka等等。Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下
- 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务
Fluentd精讲
Fluentd架构
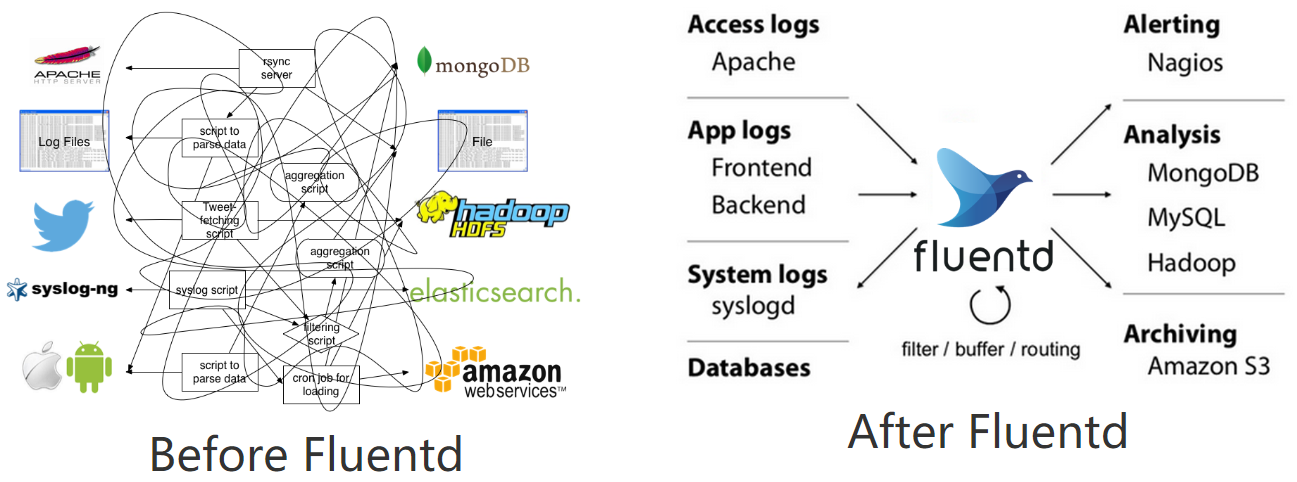
为什么推荐使用fluentd作为k8s体系的日志收集工具?
-
云原生:https://github.com/kubernetes/kubernetes/tree/release-1.21/cluster/addons/fluentd-elasticsearch
-
将日志文件JSON化

-
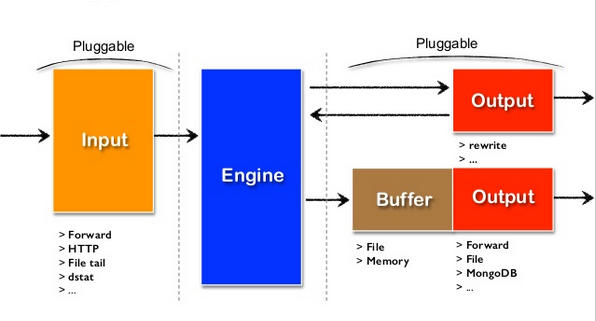
可插拔架构设计
-
极小的资源占用
基于C和Ruby语言, 30-40MB,13,000 events/second/core

-
极强的可靠性
- 基于内存和本地文件的缓存
- 强大的故障转移
fluentd事件流的生命周期及指令配置
https://docs.fluentd.org/v/0.12/quickstart/life-of-a-fluentd-event
Input -\> filter 1 -\> ... -\> filter N -\> Buffer -\> Output
启动命令
$ fluentd -c fluent.conf
指令介绍:
-
source ,数据源,对应Input 通过使用 source 指令,来选择和配置所需的输入插件来启用 Fluentd 输入源, source 把事件提交到 fluentd 的路由引擎中。使用type来区分不同类型的数据源。如下配置可以监听指定文件的追加输入:
<source>
@type tail
path /var/log/httpd-access.log
pos_file /var/log/td-agent/httpd-access.log.pos
tag myapp.access
format apache2
</source> -
filter,Event processing pipeline(事件处理流)
filter 可以串联成 pipeline,对数据进行串行处理,最终再交给 match 输出。 如下可以对事件内容进行处理:
<source>
@type http
port 9880
</source>
<filter myapp.access>
@type record_transformer
<record>
host_param “#{Socket.gethostname}”
</record>
</filter>filter 获取数据后,调用内置的 @type record_transformer 插件,在事件的 record 里插入了新的字段 host_param,然后再交给 match 输出。
-
label指令
可以在
source里指定@label,这个 source 所触发的事件就会被发送给指定的 label 所包含的任务,而不会被后续的其他任务获取到。<source>
@type forward
</source>
<source>
### 这个任务指定了 label 为 @SYSTEM
### 会被发送给 <label @SYSTEM>
### 而不会被发送给下面紧跟的 filter 和 match
@type tail
@label @SYSTEM
path /var/log/httpd-access.log
pos_file /var/log/td-agent/httpd-access.log.pos
tag myapp.access
format apache2
</source>
<filter access.**\>
@type record_transformer
<record>
# …
</record>
</filter>
<match **\>
@type elasticsearch
# …
</match>
<label @SYSTEM>
### 将会接收到上面 @type tail 的 source event
<filter var.log.middleware.**\>
@type grep
# …
</filter>
<match **\>
@type s3
# …
</match>
</label> -
match,匹配输出
查找匹配 “tags” 的事件,并处理它们。match 命令的最常见用法是将事件输出到其他系统(因此,与 match 命令对应的插件称为 “输出插件”)
<source>
@type http
port 9880
</source>
<filter myapp.access>
@type record_transformer
<record>
host_param “#{Socket.gethostname}”
</record>
</filter>
<match myapp.access>
@type file
path /var/log/fluent/access
</match>
事件的结构:
time:事件的处理时间
tag:事件的来源,在fluentd.conf中配置
record:真实的日志内容,json对象
比如,下面这条原始日志:
192.168.0.1 - - [28/Feb/2013:12:00:00 +0900] "GET / HTTP/1.1" 200 777
经过fluentd 引擎处理完后的样子可能是:
2020-07-16 08:40:35 +0000 apache.access: {"user":"-","method":"GET","code":200,"size":777,"host":"192.168.0.1","path":"/"}
fluentd的buffer事件缓冲模型
Input -\> filter 1 -\> ... -\> filter N -\> Buffer -\> Output
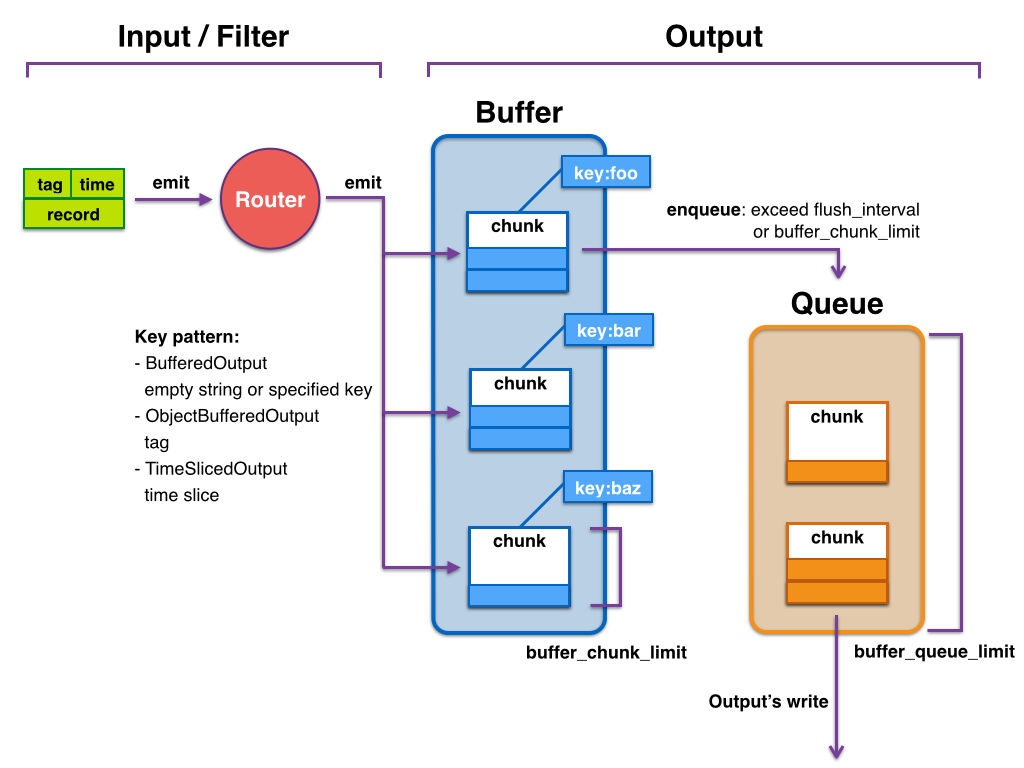
因为每个事件数据量通常很小,考虑数据传输效率、稳定性等方面的原因,所以基本不会每条事件处理完后都会立马写入到output端,因此fluentd建立了缓冲模型,模型中主要有两个概念:
- buffer_chunk:事件缓冲块,用来存储本地已经处理完待发送至目的端的事件,可以设置每个块的大小。
- buffer_queue:存储chunk的队列,可以设置长度
可以设置的参数,主要有:
- buffer_type,缓冲类型,可以设置file或者memory
- buffer_chunk_limit,每个chunk块的大小,默认8MB
- buffer_queue_limit ,chunk块队列的最大长度,默认256
- flush_interval ,flush一个chunk的时间间隔
- retry_limit ,chunk块发送失败重试次数,默认17次,之后就丢弃该chunk数据
- retry_wait ,重试发送chunk数据的时间间隔,默认1s,第2次失败再发送的话,间隔2s,下次4秒,以此类推
大致的过程为:
随着fluentd事件的不断生成并写入chunk,缓存块持变大,当缓存块满足buffer_chunk_limit大小或者新的缓存块诞生超过flush_interval时间间隔后,会推入缓存queue队列尾部,该队列大小由buffer_queue_limit决定。
比较理想的情况是每次有新的缓存块进入缓存队列,则立马会被写入到后端,同时,新缓存块也持续入列,但是入列的速度不会快于出列的速度,这样基本上缓存队列处于空的状态,队列中最多只有一个缓存块。
但是实际情况考虑网络等因素,往往缓存块被写入后端存储的时候会出现延迟或者写入失败的情况,当缓存块写入后端失败时,该缓存块还会留在队列中,等retry_wait时间后重试发送,当retry的次数达到retry_limit后,该缓存块被销毁(数据被丢弃)。
此时缓存队列持续有新的缓存块进来,如果队列中存在很多未及时写入到后端存储的缓存块的话,当队列长度达到buffer_queue_limit大小,则新的事件被拒绝,fluentd报错,error_class=Fluent::Plugin::Buffer::BufferOverflowError error="buffer space has too many data"。
还有一种情况是网络传输缓慢的情况,若每3秒钟会产生一个新块,但是写入到后端时间却达到了30s钟,队列长度为100,那么每个块出列的时间内,又有新的10个块进来,那么队列很快就会被占满,导致异常出现。