Pod数据持久化
Pod数据持久化
通过挂载卷的方式,参考mysql的pod
服务健康检查
检测容器服务是否健康的手段,若不健康,会根据设置的重启策略(restartPolicy)进行操作,两种检测机制可以分别单独设置,若不设置,默认认为Pod是健康的。
两种机制:
-
LivenessProbe探针 存活性探测:用于判断容器是否存活,即Pod是否为running状态,如果
LivenessProbe探针探测到容器不健康,则kubelet将kill掉容器,并根据容器的重启策略是否重启,如果一个容器不包含LivenessProbe探针,则Kubelet认为容器的LivenessProbe探针的返回值永远成功。...
containers:
- name: eladmin-api
image: 172.21.65.226:5000/eladmin/eladmin-api:v1
livenessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
...
# 可配置的参数如下:
initialDelaySeconds:容器启动后第一次执行探测是需要等待多少秒。
periodSeconds:执行探测的频率。默认是10秒,最小1秒。
timeoutSeconds:探测超时时间。默认1秒,最小1秒。
successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是1。
failureThreshold:探测成功后,最少连续探测失败多少次
# 本例配置的情况,健康检查的逻辑为:
K8S将在Pod开始启动20s(initialDelaySeconds)后探测Pod内的8000端口是否可以建立TCP连接,并且每15秒钟探测一次,如果连续3次探测失败,则kubelet重启该容器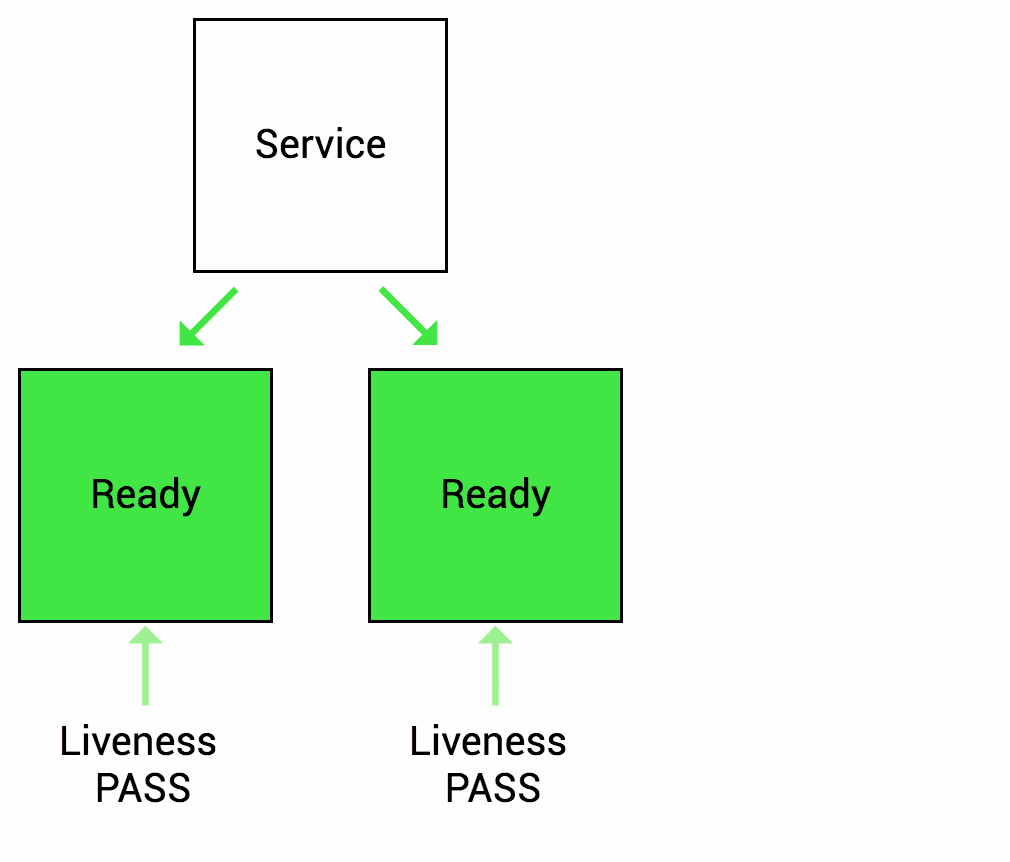
-
ReadinessProbe探针 可用性探测:用于判断容器是否正常提供服务,即容器的Ready是否为True,是否可以接收请求,如果
ReadinessProbe探测失败,则容器的Ready将为False,Endpoint Controller控制器将此Pod的Endpoint从对应的service的Endpoint列表中移除,不再将任何请求调度此Pod上,直到下次探测成功。(剔除此pod不参与接收请求不会将流量转发给此Pod)。...
containers:
- name: eladmin-api
image: 172.21.65.226:5000/eladmin/eladmin-api:v1
readinessProbe:
httpGet:
path: /auth/code
port: 8000
scheme: HTTP
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
...
# K8S将在Pod开始启动10s(initialDelaySeconds)后利用HTTP访问8000端口的/auth/code,如果超过3s**或者返回码不在200~399内,则健康检查失败
三种类型:
-
exec:通过执行命令来检查服务是否正常,返回值为0则表示容器健康
...
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
... -
httpGet方式:通过发送http请求检查服务是否正常,返回200-399状态码则表明容器健康
containers:
- name: eladmin-api
image: 172.21.65.226:5000/eladmin/eladmin-api:v1
readinessProbe:
httpGet:
path: /auth/code
port: 8000
scheme: HTTP
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间 -
tcpSocket:通过容器的IP和Port执行TCP检查,如果能够建立TCP连接,则表明容器健康
...
livenessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
...
以Redis为例,演示效果:
apiVersion: v1
kind: Pod
metadata:
name: redis
namespace: luffy
labels:
app: redis
spec:
# hostNetwork: true
containers:
- name: redis
image: redis:3.2
ports:
- containerPort: 6379
livenessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
readinessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10
timeoutSeconds: 2
periodSeconds: 10
> Readiness 决定了Service是否将流量导入到该Pod,Liveness决定了容器是否需要被重启
重启策略
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应的操作。
Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
- Always:当容器进程退出后,由
kubelet自动重启该容器; - OnFailure:当容器终止运行且退出码不为0时,由
kubelet自动重启该容器; - Never:不论容器运行状态如何,
kubelet都不会重启该容器。
演示重启策略:
1. eladmin-api 服务连接不上数据库的情况下,分别设置三种重启策略,观察Pod的重启表现
- 使用默认的重启策略,即
restartPolicy: Always,无论容器是否是正常退出,都会自动重启容器 - 使用
OnFailure的策略时- 如果Pod的1号进程是正常退出,则不会重启
- 只有非正常退出状态才会重启
- 使用Never时,退出了就不再重启
可以看出,若容器正常退出,Pod的状态会是Completed,非正常退出,状态为Error或者CrashLoopBackOff
镜像拉取策略
spec:
containers:
- name: eladmin-api
image: 172.21.65.226:5000/eladmin/eladmin-api:v1
imagePullPolicy: IfNotPresent
设置镜像的拉取策略,默认为IfNotPresent
- Always,总是拉取镜像,即使本地有镜像也从仓库拉取
- IfNotPresent ,本地有则使用本地镜像,本地没有则去仓库拉取
- Never,只使用本地镜像,本地没有则报错
Pod资源限制
为了保证充分利用集群资源,且确保重要容器在运行周期内能够分配到足够的资源稳定运行,因此平台需要具备
Pod的资源限制的能力。 对于一个pod来说,资源最基础的2个的指标就是:CPU和内存。
Kubernetes提供了个采用requests和limits 两种类型参数对资源进行预分配和使用限制。
...
apiVersion: v1
kind: Pod
metadata:
name: redis
namespace: luffy
labels:
app: redis
spec:
containers:
- name: redis
image: redis:3.2
ports:
- containerPort: 6379
livenessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
readinessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
resources:
requests:
memory: 300Mi
cpu: 50m
limits:
memory: 1Gi
cpu: 200m
...
requests:
- 容器使用的最小资源需求,作用于schedule阶段,作为容器调度时资源分配的判断依赖
- 只有当前节点上可分配的资源量 >= request 时才允许将容器调度到该节点
- request参数不限制容器的最大可使用资源
- requests.cpu被转成docker的--cpu-shares参数,与cgroup cpu.shares功能相同 (无论宿主机有多少个cpu或者内核,--cpu-shares选项都会按照比例分配cpu资源)
- requests.memory没有对应的docker参数,仅作为k8s调度依据
limits:
- 容器能使用资源的最大值
- 设置为0表示对使用的资源不做限制, 可无限的使用
- 当pod 内存超过limit时,会被oom
- 当cpu超过limit时,不会被kill,但是会限制不超过limit值
- limits.cpu会被转换成docker的–cpu-quota参数。与cgroup cpu.cfs_quota_us功能相同
- limits.memory会被转换成docker的–memory参数。用来限制容器使用的最大内存
对于 CPU,我们知道计算机里 CPU 的资源是按“时间片”的方式来进行分配的,系统里的每一个操作都需要 CPU 的处理,所以,哪个任务要是申请的 CPU 时间片越多,那么它得到的 CPU 资源就越多。
然后还需要了解下 CGroup 里面对于 CPU 资源的单位换算:
1 CPU = 1000 millicpu(1 Core = 1000m)
这里的 m 就是毫、毫核的意思,Kubernetes 集群中的每一个节点可以通过操作系统的命令来确认本节点的 CPU 内核数量,然后将这个数量乘以1000,得到的就是节点总 CPU 总毫数。比如一个节点有四核,那么该节点的 CPU 总毫量为 4000m。
> 注意:若内存使用超出限制,会引发系统的OOM机制,因CPU是可压缩资源,不会引发Pod退出或重建
改造后yaml
redis.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
namespace: luffy
labels:
app: redis
spec:
containers:
- name: redis
image: redis:3.2
ports:
- containerPort: 6379
livenessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
readinessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
resources:
requests:
memory: 100Mi
cpu: 50m
limits:
memory: 4Gi
cpu: 2
mysql.yaml
apiVersion: v1
kind: Pod
metadata:
name: mysql
namespace: luffy
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_DATABASE # 指定数据库地址
value: "eladmin"
- name: MYSQL_ROOT_PASSWORD
value: "luffyAdmin!"
ports:
- containerPort: 3306
args:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
livenessProbe:
tcpSocket:
port: 3306
initialDelaySeconds: 15 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
readinessProbe:
tcpSocket:
port: 3306
initialDelaySeconds: 15 # 容器启动后第一次执�行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
resources:
requests:
memory: 200Mi
cpu: 50m
limits:
memory: 1Gi
cpu: 500m
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
volumes:
- name: mysql-data
hostPath:
path: /opt/mysql/
nodeSelector: # 使用节点选择器将Pod调度到指定label的节点
mysql: "true"
eladmin-api.yaml
apiVersion: v1
kind: Pod
metadata:
name: eladmin-api
namespace: luffy
labels:
app: eladmin-api
spec:
imagePullSecrets:
- name: registry-172-21-65-226
restartPolicy: Always
containers:
- name: eladmin-api
image: 172.21.65.226:5000/eladmin/eladmin-api:v1
env:
- name: DB_HOST # 指定数据库地址
value: "10.99.14.241"
- name: DB_USER # 指定数据库连接使用的用户
value: "root"
- name: DB_PWD
value: "luffyAdmin!"
- name: REDIS_HOST
value: "10.105.226.34"
- name: REDIS_PORT
value: "6379"
ports:
- containerPort: 8000
livenessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
readinessProbe:
httpGet:
path: /auth/code
port: 8000
scheme: HTTP
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
resources:
requests:
memory: 200Mi
cpu: 50m
limits:
memory: 3Gi
cpu: 2