Go的字符与字节
go语⾔的string是⼀种数据类型,这个数据类型占⽤16字节空间,前8字节是⼀个指针,指向字符串值的地址,后⼋个字节是⼀个整数,标识字 符串的长度;
(1)字符串的存储原理
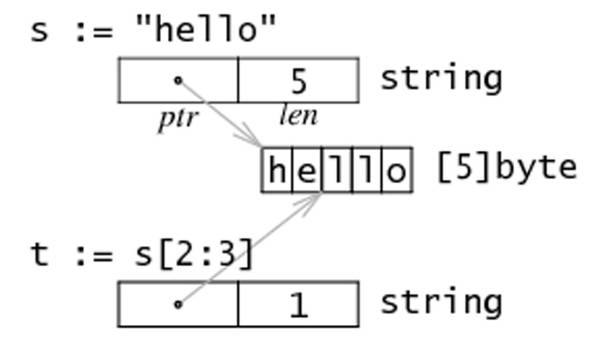
string 数据结构:源码包src/runtime/string.go:stringStruct定义了string的数据结构:
type stringStruct struct {
str unsafe.Pointer
len int
}
其数据结构很简单:
stringStruct.str:字符串的首地址;
stringStruct.len:字符串的长度;
string数据结构跟切片有些类似,只不过切片还有一个表示容量的成员,事实上string和切片,准确的说是byte切片经常发生转换。这个后面再详细介绍。
s1 := "hello"
s2 := s1[:]
s3 := s1[1:]
fmt.Println(&s1, (*reflect.StringHeader)(unsafe.Pointer(&s1)))
fmt.Println(&s2, (*reflect.StringHeader)(unsafe.Pointer(&s2)))
fmt.Println(&s3, (*reflect.StringHeader)(unsafe.Pointer(&s3)))
/*
A string type represents the set of string values. A string value is a (possibly empty) sequence of bytes. Strings are immutable: once created, it is impossible to change the contents of a string. The predeclared string type is string.
The length of a string s (its size in bytes) can be discovered using the built-in function len. The length is a compile-time constant if the string is a constant. A string's bytes can be accessed by integer indices 0 through len(s)-1. It is illegal to take the address of such an element; if s[i] is the i'th byte of a string, &s[i] is invalid.
*/
字符串类型表示字符串值的集合。字符串值是一个字节序列(可能为空)。字符串是不可变的:一旦创建,就不可能改变字符串的内容。预先声明的字符串类型是string。
字符串s的长度(以字节为单位的大小)可以使用内置函数len来发现。如果字符串是常量,则长度为编译时常量。字符串的字节可以通过索引0到len(s)-1的整数来访问。取这样一个元素的地址是非法的;如果s[i]是字符串的第i个字节,&s[i]是无效的。
go语⾔指针和C/C++指针的唯⼀差别就是:go语⾔不允许对指针做算术运算(+、-、++、--)。
但是,Go提供了⼀套底层库reflect和unsafe,它们可以把任意⼀个go指针转成uintptr类型的值,然后再像C/C++⼀样对指针做算术运算,最后再还原成go类型。所以从这个⾓度上看,go指针也是可以和C/C++指针⼀样使⽤的,只是会⽐较绕,这同时也要求使⽤者⾃⼰明⽩,如果真要把指针这么⽤,那么请记得后果⾃负。
(2)字符串的使用
// 本质上,unicode是一个编码集,和ascii码相同,而utf8是编码规则
var a = '袁'
fmt.Printf("字符'袁'unicode的十进制:%d\n", a)
fmt.Printf("字符'袁'unicode的十六进制:%x\n", a)
fmt.Printf("字符'袁'unicode的二进制:%b\n", a)
var b = 0b111010001000101110010001
fmt.Printf("字符'袁'的utf8:%x\n", b)
var c = "袁abc"
fmt.Println(c) // 袁abc
for i := 0; i < len(c); i++ {
fmt.Printf("%d\n", c[i]) // 存储的字节的十进制数
}
for _, v := range c {
fmt.Printf("%d,%c\n", v, v) // 通过存储的utf8解析到unicode值和对应的符号
}
UTF-8的编码规则:
(1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
(2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
举例说明:
已知'袁'的unicode是82d1(1000001011010001),'袁'的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从'袁'的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,'袁'的UTF-8编码是 “111010001 00010111 0010001”,转换成十六进制就是e88b91。
(3)字符串与字节串的转换
字节数组,就是一个数组,里面每一个元素都是字符,字符又跟字节划等号。所以字符串和字节数组之间可以相互转化。
// (1) 字符串类型(string) 转为字节串类型([]byte)
var s = "小袁"
fmt.Println(s,reflect.TypeOf(s)) // 小袁 string
var b = []byte(s) // 默认用uft-8进行编码
fmt.Println(b,reflect.TypeOf(b))
// 可以通过代码 len([]rune(s)) 来获得字符串中字符的数量, 但使用 utf8.RuneCountInString(s) 效率会更高一点.
s := "Hello,世界"
r1 := []byte(s)
r2 := []rune(s)
fmt.Println(r1) // 输出:[72 101 108 108 111 44 32 228 184 150 231 149 140]
fmt.Println(r2) // 输出:[72 101 108 108 111 44 32 19990 30028]
// 统计字节个数
fmt.Println(len(r1))
// 统计字符个数
fmt.Println(len(r2))
fmt.Println(utf8.RuneCountInString(s))
// (2) byte转为string
fmt.Println(string(b))
var data = []byte{121,117,97,110}
fmt.Println(string(data)) // yuan
这里的转化不是将string结构体中指向的byte切片直接做赋值操作,而是通过copy实现的,在数据量比较大时,这里的转化会比较耗费内存空间。
(4)练习
将字符串 "hello" 转换为 "cello"
s := "hello"
c := []byte(s)
c[0] = 'c'
s2 := string(c) //s2 == "cello"
将字符串 "hello" 反转
func reverseString(s []byte) []byte {
var i, j = 0, len(s) - 1
for i < j {
s[i], s[j] = s[j], s[i]
i++
j--
}
return s
}