helm3 chart开发
· 阅读需 5 分钟
安装helm3
#wget https://docs.rancher.cn/download/helm/helm-v3.3.0-linux-amd64.tar.gz
wget https://get.helm.sh/helm-v3.9.2-linux-amd64.tar.gz #下载helm安装包
tar -zxvf helm-v3.3.0-linux-amd64.tar.gz #解压安装包
cp linux-amd64/helm /usr/local/bin/
helm version #检验是否安装成功

helm自动补全�
source <(helm completion bash)
echo "source <(helm completion bash)" >> ~/.bashrc
source ~/.bashrc
helm常用命令
| 命令 | 用法 | 描述 |
|---|---|---|
| create | helm create NAME [flags] | create a new chart with the given name |
| install | helm install [NAME] [CHART] [flags] | installs a chart |
| pull | helm pull [chart URL |repo/chartname] [...] [flags] | download a chart from a repository and (optionally) unpack it in local directory |
| repo | helm repo ... | add, list, remove, update, and index chart repositories |
| search | helm search [command] ( repo/hub ) | search for a keyword in charts |
| uninstall | helm uninstall RELEASE_NAME [...] [flags] | uninstall a release |
| upgrade | helm upgrade [RELEASE] [CHART] [flags] | upgrade a release |
创建chart包
helm create httpbin #创建httpbin chart
查看httpbin的目录结构
sudo apt install tree #安装tree
tree httpbin -a
httpbin
├── charts
├── Chart.yaml
├── .helmignore
├── templates
│ ├── deployment.yaml
│ ├── _helpers.tpl
│ ├── ingress.yaml
│ ├── NOTES.txt
│ ├── serviceaccount.yaml
│ ├── service.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yaml
3 directories, 10 files
Chart包文件结构
Helm规范了Chart的目录和文件结构,这些目录或者文件都有确定的用途。
- charts/,包含其它Chart,称之为Sub Chart,或者依赖Chart。
- Chart.yaml,包含Chart的说明,可在从模板中访问Chart定义的值。
- .helmignore,定义了在helm package时哪些文件不会打包到Chart包tgz中。
- ci/,缺省没有该目录,持续集成的一些脚本。
- templates/,用于放置模板文件,主要定义提交给Kubernetes的资源yaml文件。安装Chart时,Helm会根据chart.yaml、values.yam以及命令行提供的值对Templates进行渲染,最后会将渲染的资源提交给Kubernetes。
- _helpers.tpl,定义了一些可重用的模板片断,此文件中的定义在任何资源定义模板中可用。
- NOTES.txt,提供了安装后的使用说明,在Chart安装和升级等操作后,
- tests/,包含了测试用例。测试用例是pod资源,指定一个的命令来运行容器。容器应该成功退出(exit 0),测试被认为是成功的。该pod定义必须包含helm测试hook注释之一:helm.sh/hook: test-success或helm.sh/hook: test-failure。
- values.yaml,values文件对模板很重要,该文件包含Chart默认值。Helm渲染template时使用这些值
修改values.yaml
修改values.yaml如下,用于Helm渲染template
- 将镜像改为image.repository=docker.io/kennethreitz/httpbin。
- 不创建serviceAccount,serviceAccount.create=false
- 为了Kubernetes集群外能访问Service,将type改为NodePort。并增加一个参数,为nodePort配置一个固定端口
cd httpbin/
vi values.yaml
# Default values for httpbin.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
replicaCount: 1
image:
repository: docker.io/kennethreitz/httpbin #修改镜像为httpbin
pullPolicy: IfNotPresent
# Overrides the image tag whose default is the chart appVersion.
tag: latest
imagePullSecrets: []
nameOverride: ""
fullnameOverride: ""
serviceAccount:
# Specifies whether a service account should be created
create: false #不创建serviceAccount,改为false
# Annotations to add to the service account
annotations: {}
# The name of the service account to use.
# If not set and create is true, a name is generated using the fullname template
name: ""
podAnnotations: {}
podSecurityContext: {}
# fsGroup: 2000
securityContext: {}
# capabilities:
# drop:
# - ALL
# readOnlyRootFilesystem: true
# runAsNonRoot: true
# runAsUser: 1000
service:
type: NodePort #将type改为NodePort
port: 80
nodePort: 30080 #为NodePort配置一个固定端口
ingress:
enabled: false
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
hosts:
- host: chart-example.local
paths: []
tls: []
# - secretName: chart-example-tls
# hosts:
# - chart-example.local
resources: {}
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources, such as Minikube. If you do want to specify resources, uncomment the following
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
# limits:
# cpu: 100m
# memory: 128Mi
# requests:
# cpu: 100m
# memory: 128Mi
autoscaling:
enabled: false
minReplicas: 1
maxReplicas: 100
targetCPUUtilizationPercentage: 80
# targetMemoryUtilizationPercentage: 80
nodeSelector: {}
tolerations: []
affinity: {}
修改service.yaml
由于配置了固定的nodePort,所以在service.yaml中增加该参数,并引用了对应的value值
vi templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: {{ include "httpbin.fullname" . }}
labels:
{{- include "httpbin.labels" . | nindent 4 }}
spec:
type: {{ .Values.service.type }}
ports:
- port: {{ .Values.service.port }}
targetPort: http
protocol: TCP
name: http
nodePort: {{ .Values.service.nodePort }} #新增参数
selector:
{{- include "httpbin.selectorLabels" . | nindent 4 }}
查看渲染后结果
helm template my-release httpbin
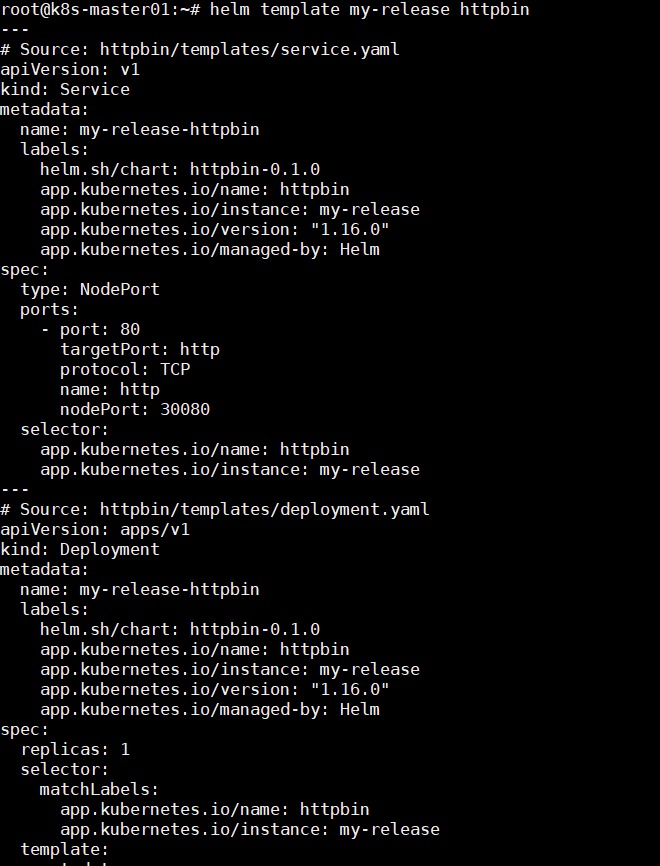
安装httpbin
渲染没有问题后开始安装httpbin
helm install my-release httpbin
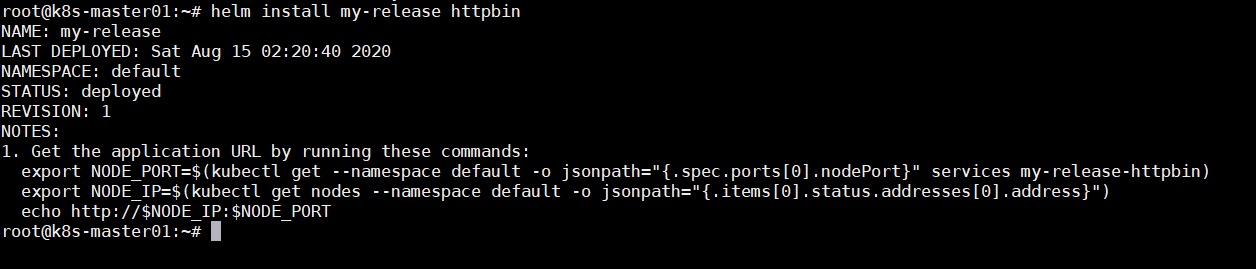
访问httpbin
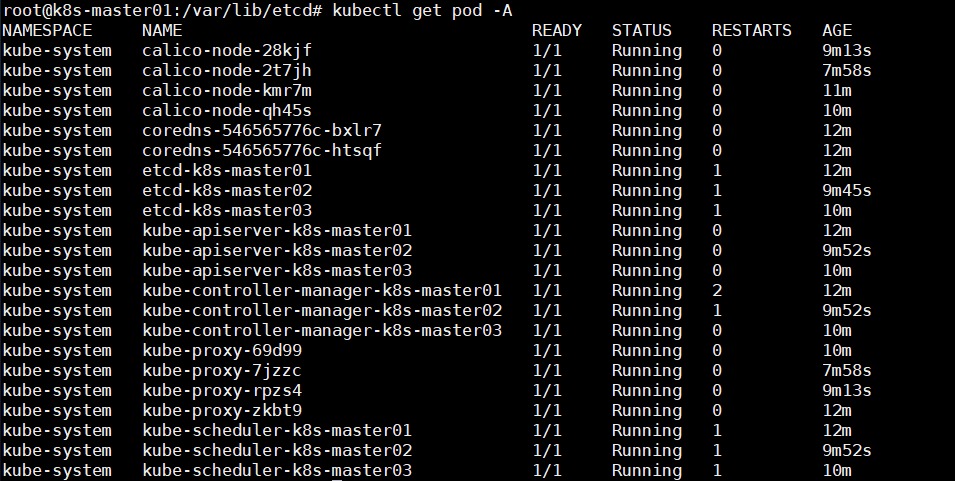
kubectl get pod #观察httpbin是否部署成功

访问 http://IP:30080
打包chart
部署成功后可将chart进行打包
helm package httpbin